
Bloom filter is a data structure that allows to save a lot of memory when checking if an element exists in a set at the expense of some precision. Let’s see how it works and what are the guarantees.
The Bloom Filter Purpose and the Guarantees
Suppose there is a gigantic set of some sort. In order to check whether an element exists in the set we would need to keep it in memory in its entirety. Of course, we can keep the data set on disk, but accessing it won’t be as fast as checking if an element exists in a hash map.
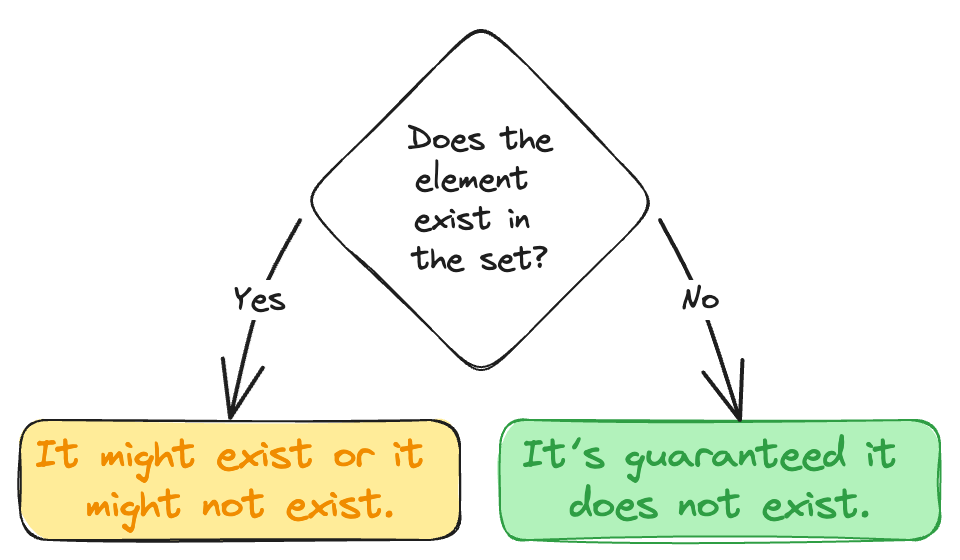
A Bloom filter also allows checking if an element belongs to a set, but it requires way less memory for that. This comes with the cost of the check not always being precise. In particular if the filter says an element exists in a set then it might exist, or it might not. Luckily the guarantee in the opposite case is stronger: if the filter says an element does not exist in a set then it’s guaranteed it does not exist.
For example suppose there is a task to check if a password has ever been leaked. Keeping a set of all passwords that have ever been exposed in data breaches would have required a lot of memory. Instead, we could build a Bloom filter once and check new passwords against it. It’s fast and space efficient. According to the Bloom filter guarantees if a password is not known to the filter we can be sure it has never been exposed.
How do Bloom Filters Work
To construct a Bloom filter we need a hash function hash() and a bit array bloom []bit of size n. Now if we want to add "foo" to the filter all we do is we pass "foo" through the hash function, take % n of the result and set the corresponding bit in the bit array: bloom[hash("foo") % n] = 1.
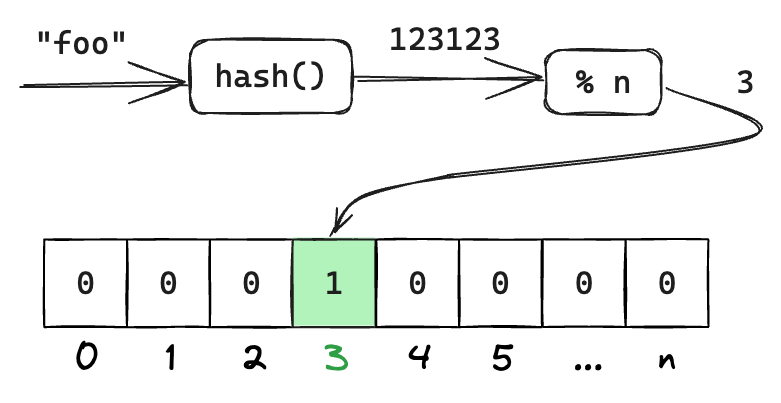
To check if an entry exists in the filter we calculate the array index in the same way and check if it’s set.
False-Positives
If n is small enough there is a high chance two distinct entries are going to produce the same array index. Even if n is big there is still a possibility of that happening. If one such entry is added to the filter, and we check if another one exists in the filter the response is going to be “Yes”, although it’s wrong. This is a false-positive result.
In order to counter combat this usually more than one hash function is used. When adding an entry to the Bloom filter all bits that correspond to each hash function are set. And when checking if an entry belongs to the filter all bits are checked. If at least one is 0 then “No” is returned as the outcome.
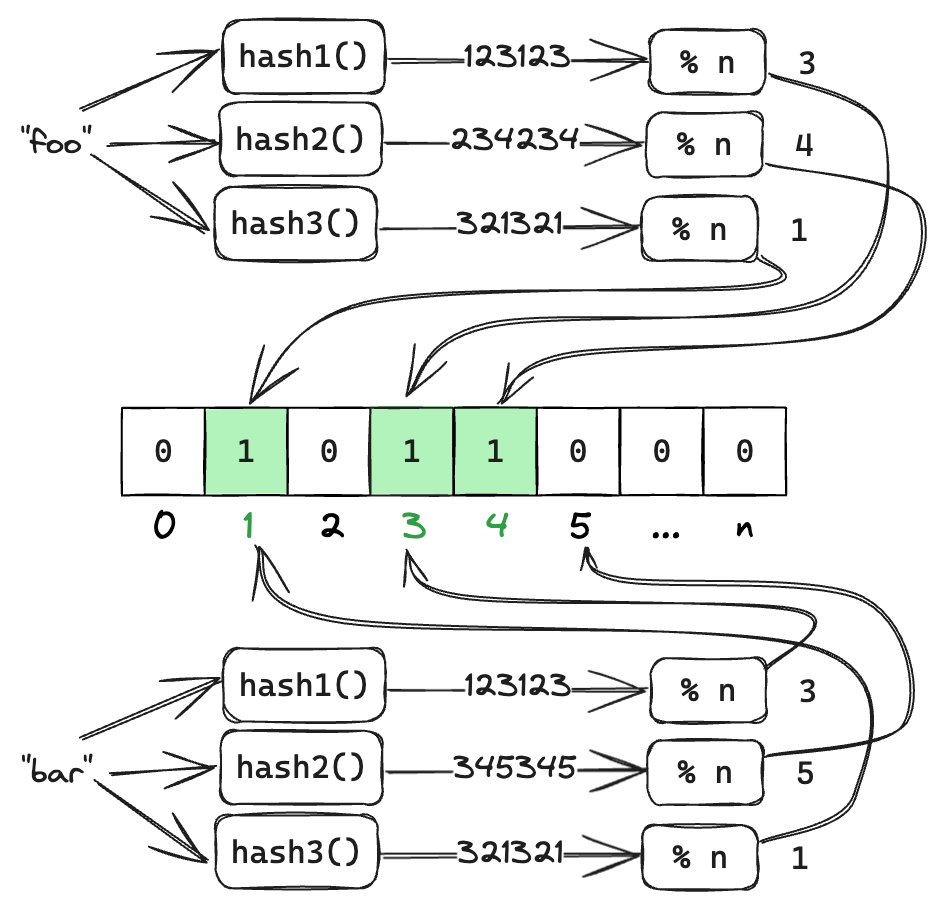
On the figure above 3 hash functions are used. First the entry "foo" is added to the filter. For that bits 1, 3 and 4 are set.
Later the entry "bar" is being tested against the filter. Hash functions hash1 and hash3 produce false-positives, and hash2 produces a negative result. Despite two false-positives one negative result means "bar" is not known to the filter.
Bloom Filters in Practice
By varying the Bloom filter array size and the number of hash functions we can limit the possibility of a false-positive outcome down to an acceptable level. These parameters can be mathematically calculated. In practice there is no need to do that as most of the implementations provide means to estimate the parameters.
For example when creating a Bloom filter in Redis we pass the approximate number of entries we have in the set and the desired false-positive rate.
A popular Golang implementation allows creating a Bloom filter either by setting the array size and the number of hash functions manually or by doing it the same way Redis does it.
Guava’s implementation allows creating a filter by specifying the expected size of the set. A default false-positives probability of 3% is used, or it can be customized.
It’s important to collect metrics for each Bloom filter in the system. Knowing how many checks were done against a filter and how many of them were false-positives would allow alerting in case the rate of false-positives goes above the desired level. In this case the filter can be rebuilt using different parameters.